A
gent-
B
ased
E
volutionary
D
ynamics
Luis R. Izquierdo, Segismundo S. Izquierdo & William H. Sandholm
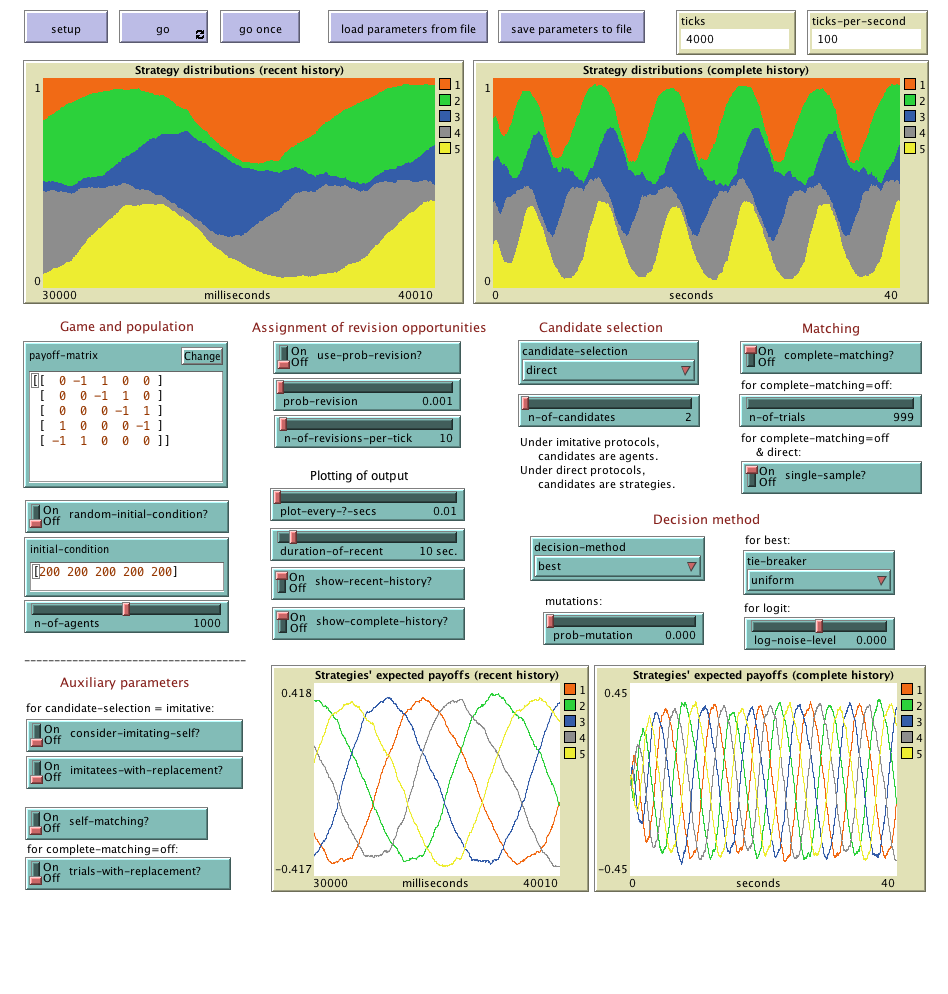
Abed-1pop
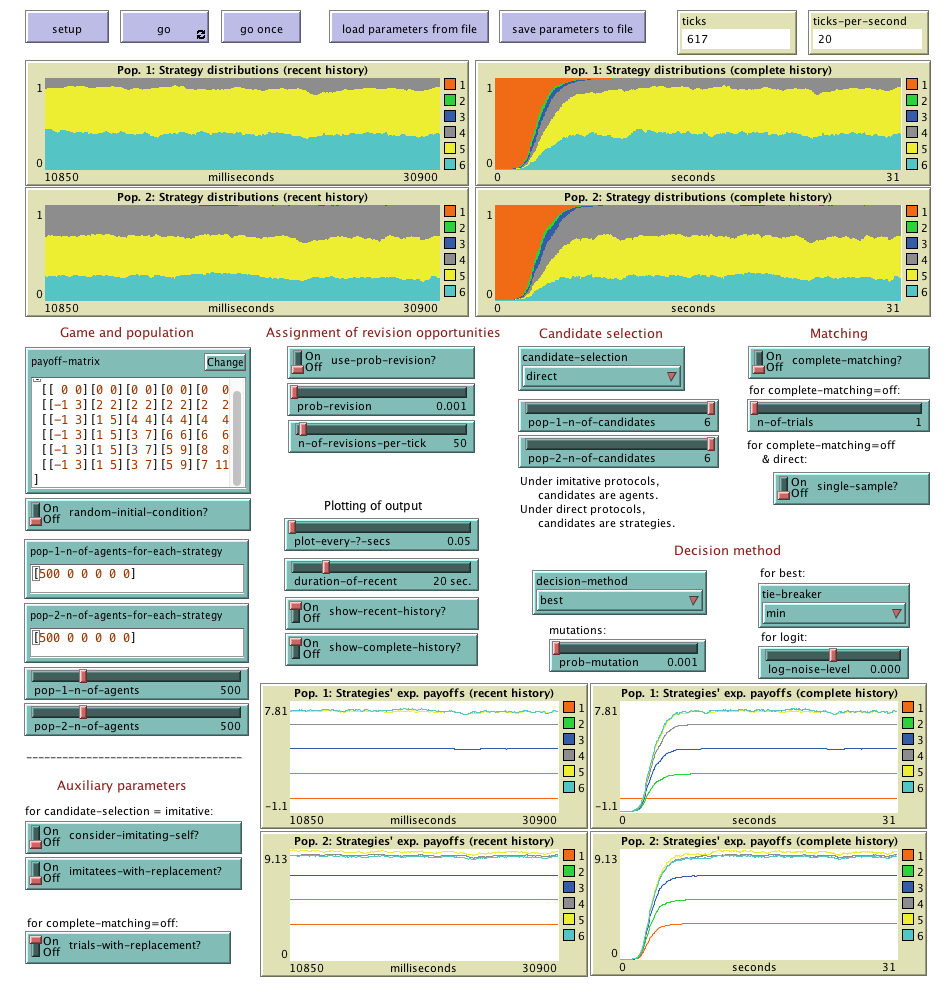
Abed-2pop
© Luis R. Izquierdo, Segismundo S. Izquierdo & William H. Sandholm 2017